A New Google AI Research Proposes Deep-Thinking Ratio to Improve LLM Accuracy While Cutting Total Inference Costs by Half

For the last few years, the AI world has followed a simple rule: if you want a Large Language Model (LLM) to solve a harder problem, make its Chain-of-Thought (CoT) longer. But new research from the University of Virginia and Google proves that ‘thinking long’ is not the same as ‘thinking hard’.
The research team reveals that simply adding more tokens to a response can actually make an AI less accurate. Instead of counting words, the Google researchers introduce a new measurement: the Deep-Thinking Ratio (DTR).
The Failure of ‘Token Maxing‘
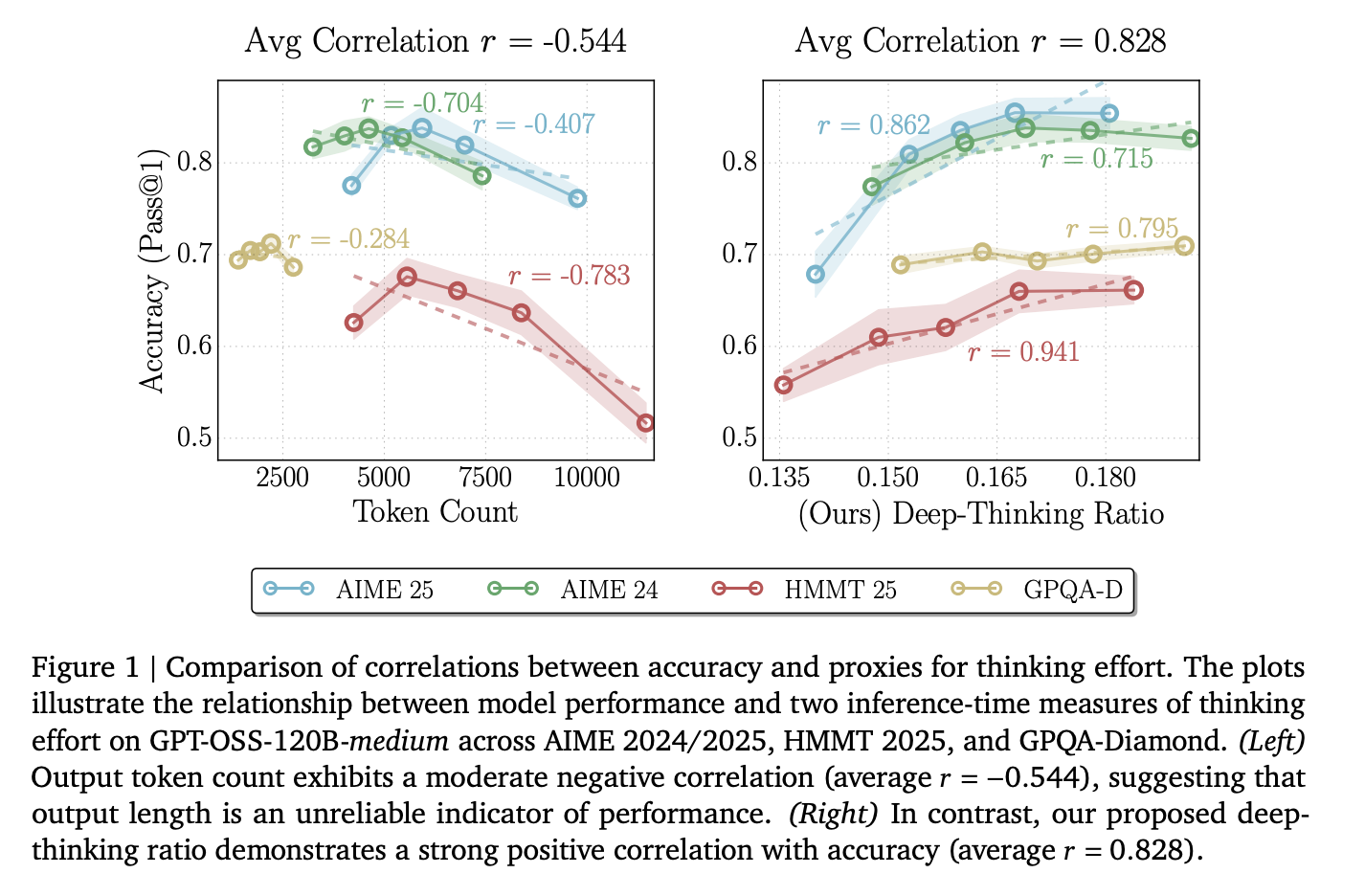
Engineers often use token count as a proxy for the effort an AI puts into a task. However, the researchers found that raw token count has an average correlation of r= -0.59 with accuracy.
This negative number means that as the model generates more text, it is more likely to be wrong. This happens because of ‘overthinking,’ where the model gets stuck in loops, repeats redundant steps, or amplifies its own mistakes. Relying on length alone wastes expensive compute on uninformative tokens.

What are Deep-Thinking Tokens?
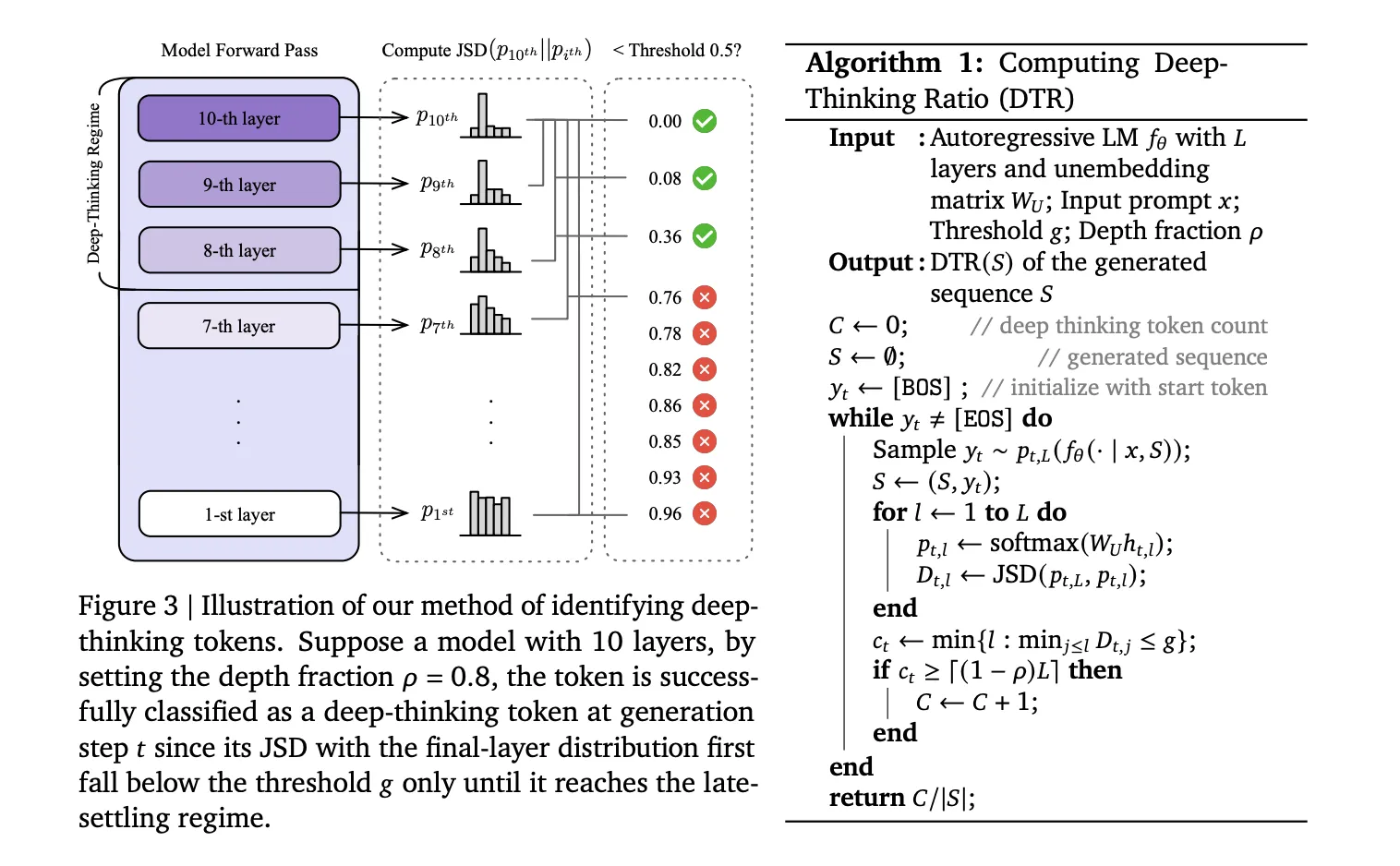
The research team argued that real ‘thinking’ happens inside the layers of the model, not just in the final output. When a model predicts a token, it processes data through a series of transformer layers (L).
Shallow Tokens: For easy words, the model’s prediction stabilizes early. The ‘guess’ doesn’t change much from layer 5 to layer 36.
Deep-Thinking Tokens: For difficult logic or math symbols, the prediction shifts significantly in the deeper layers.
How to Measure Depth
To identify these tokens, the research team uses a technique to peek at the model’s internal ‘drafts’ at every layer. They project the intermediate hidden states (htl) into the vocabulary space using the model’s unembedding matrix (WU). This produces a probability distribution (pt,l) for every layer.
They then calculate the Jensen-Shannon Divergence (JSD) between the intermediate layer distribution and the final layer distribution (pt,L):
Dt,l := JSD(pt,L || pt,l)
A token is a deep-thinking token if its prediction only settles in the ‘late regime’—defined by a depth fraction (⍴). In their tests, they set ⍴= 0.85, meaning the token only stabilized in the final 15% of the layers.
The Deep-Thinking Ratio (DTR) is the percentage of these ‘hard’ tokens in a full sequence. Across models like DeepSeek-R1-70B, Qwen3-30B-Thinking, and GPT-OSS-120B, DTR showed a strong average positive correlation of r = 0.683 with accuracy.
Think@n: Better Accuracy at 50% the Cost
The research team used this innovative approach to create Think@n, a new way to scale AI performance during inference.
Most devs use Self-Consistency (Cons@n), where they sample 48 different answers and use majority voting to pick the best one. This is very expensive because you have to generate every single token for every answer.
Think@n changes the game by using ‘early halting’:
The model starts generating multiple candidate answers.
After just 50 prefix tokens, the system calculates the DTR for each candidate.
It immediately stops generating the ‘unpromising’ candidates with low DTR.
It only finishes the candidates with high deep-thinking scores.
The Results on AIME 2025
On the AIME 25 math benchmark, Think@n achieved higher accuracy than standard voting while reducing the inference cost by 49%.
Key Takeaways
Token count is a poor predictor of accuracy: Raw output length has an average negative correlation (r = -0.59) with performance, meaning longer reasoning traces often signal ‘overthinking’ rather than higher quality.
Deep-thinking tokens define true effort: Unlike simple tokens that stabilize in early layers, deep-thinking tokens are those whose internal predictions undergo significant revision in deeper model layers before converging.
The Deep-Thinking Ratio (DTR) is a superior metric: DTR measures the proportion of deep-thinking tokens in a sequence and exhibits a robust positive correlation with accuracy (average r = 0.683), consistently outperforming length-based or confidence-based baselines.
Think@n enables efficient test-time scaling: By prioritizing and finishing only the samples with high deep-thinking ratios, the Think@n strategy matches or exceeds the performance of standard majority voting (Cons@n).
Massive cost reduction via early halting: Because DTR can be estimated from a short prefix of just 50 tokens, unpromising generations can be rejected early, reducing total inference costs by approximately 50%.
Check out the Paper. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.