
They Hated It Because They Thought It Was AI… #ai #news #technology
Check on YouTube

Check on YouTube
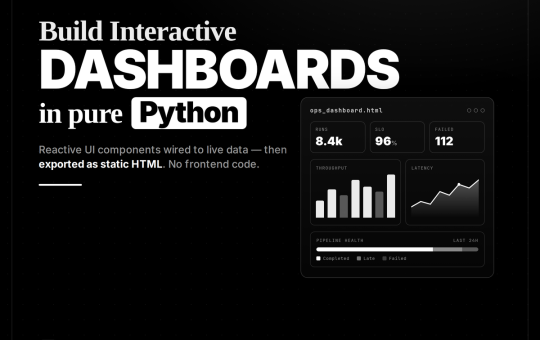
import random from collections import Counter, defaultdict from datetime import date, timedelta from prefab_ui.actions import AppendState, OpenLink, PopState, SetState, ShowToast,...
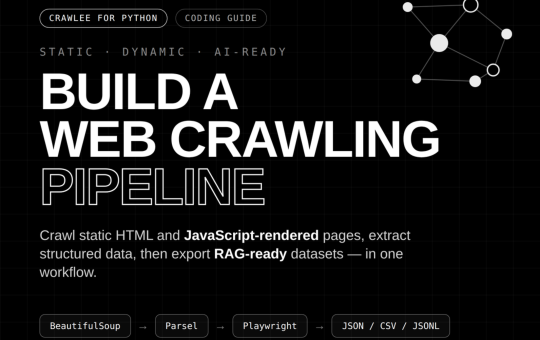
PRODUCTS = , "related": , }, { "sku": "CRW-202", "name": "Playwright Rendering Pack", "category": "browser", "price": 249.0, "rating": 4.7, "stock":...

Getting prompts right is still the hardest part of shipping reliable LLM applications. Small wording changes can swing accuracy by...

TLDR YaFF is Yandex’s open-source zero-copy wire format for Protobuf — Apache 2.0, currently C++, v0.1.0. The .proto file stays...

Check on YouTube
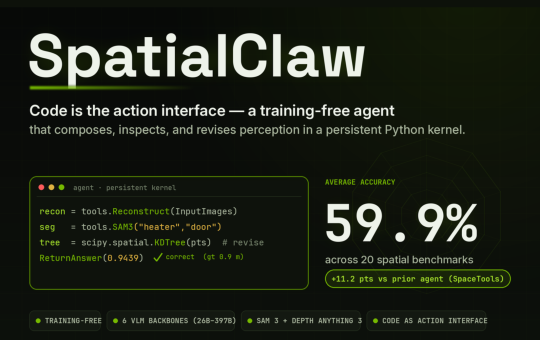
NVIDIA Research has released SpatialClaw, a training-free framework for spatial reasoning. It targets a persistent weakness in vision-language models (VLMs)....

This week, Liquid AI released two new retrieval models. They are LFM2.5-ColBERT-350M and LFM2.5-Embedding-350M. Both hold 350M parameters. Both are...

Check on YouTube

Most AI memory remembers the user. It stores your preferences, your tastes, and your role. Perplexity is taking a different...
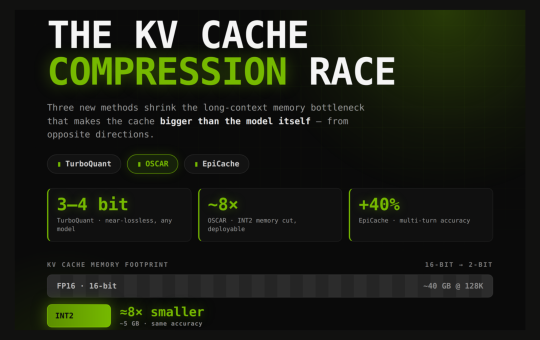
Long-context large language models (LLMs) face a memory bottleneck that has nothing to do with model weights. During decoding, transformers...

Check on YouTube
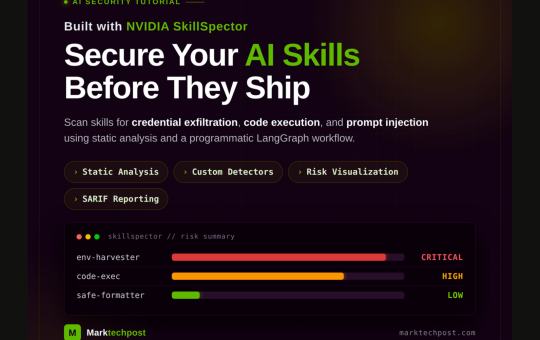
print("Batch scanning the whole corpus (static-only)...\n") summary_rows = all_findings = for skill in SKILLS: res = scan(skill, use_llm=False, output_format="json") fnds...
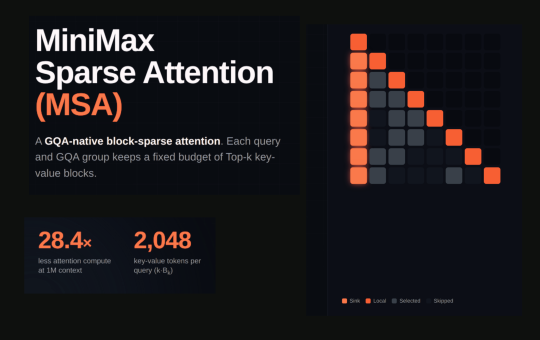
MiniMax released MSA (MiniMax Sparse Attention), a sparse attention method built directly on Grouped Query Attention (GQA). It targets one...

Check on YouTube
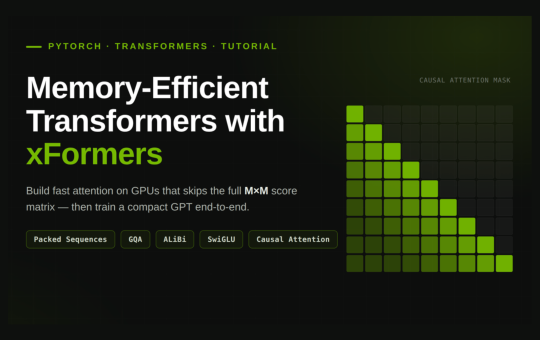
print("\n" + "="*70 + "\n4. Variable-length packed batch — no padding waste\n" + "="*70) seqlens = total = sum(seqlens) H,...

Nous Research has shipped a change to Hermes Agent. Its delegate tool can now run subagents asynchronously. Per the announcement,...

Tokyo-based Sakana AI shipped its first commercial product ‘Sakana Marlin’ this week. Sakana team positions it as a Virtual CSO...

k-means has been an offline tool for decades. You run it once to preprocess data, then move on. A team...






