Meta Superintelligence Lab Releases Muse Spark: A Multimodal Reasoning Model With Thought Compression and Parallel Agents

Meta Superintelligence Labs recently made a significant move by unveiling ‘Muse Spark’ — the first model in the Muse family. Muse Spark is a natively multimodal reasoning model with support for tool-use, visual chain of thought, and multi-agent orchestration.
What ‘Natively Multimodal’ Actually Means
When Meta describes Muse Spark as ‘natively multimodal,’ it means the model was trained from the ground up to process and reason across text and visual inputs simultaneously — not a vision module bolted onto a language model after the fact. Muse Spark is built from the ground up to integrate visual information across domains and tools, achieving strong performance on visual STEM questions, entity recognition, and localization.
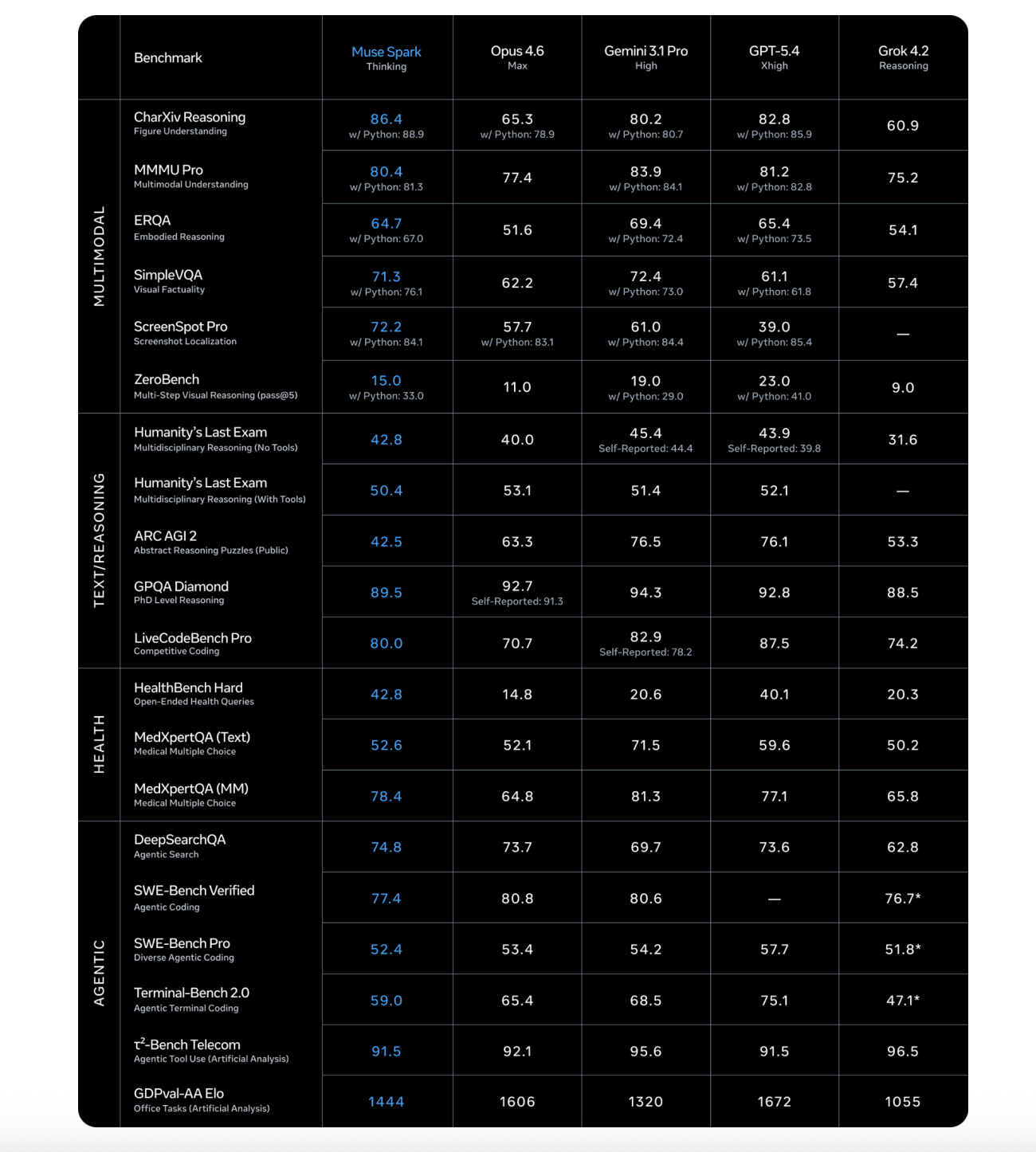
This architectural choice has real consequences on tasks that combine language and vision. On the ScreenSpot Pro benchmark — which tests screenshot localization, requiring the model to identify specific UI elements in images — Muse Spark scores 72.2 (84.1 with Python tools), compared to Claude Opus 4.6 Max’s 57.7 (83.1 with Python) and GPT-5.4 Xhigh’s 39.0 (85.4 with Python).
Three Scaling Axes: Pretraining, RL, and Test-Time Reasoning
The most technically interesting part of the Muse Spark announcement is Meta’s explicit framing around three scaling axes — the levers they’re pulling to improve model capability in a predictable and measurable way. To support further scaling across all three, Meta is making strategic investments across the entire stack — from research and model training to infrastructure, including the Hyperion data center.

Pretraining is where the model learns its core world knowledge, reasoning, and coding abilities. Over the last nine months, Meta rebuilt its pretraining stack with improvements to model architecture, optimization, and data curation. The payoff is substantial efficiency gains: Meta can reach the same capabilities with over an order of magnitude less compute than its previous model, Llama 4 Maverick. For devs, ‘an order of magnitude’ means roughly 10x more compute-efficient — a major improvement that makes larger future models more financially and practically viable.
Reinforcement Learning (RL) is the second axis. After pretraining, RL is applied to amplify capabilities by training the model on outcome-based feedback rather than just token prediction. Think of it this way: pretraining teaches the model facts and patterns; RL teaches it to actually get answers right. Even though large-scale RL is notoriously prone to instability, Meta’s new stack delivers smooth, predictable gains. The research team reports log-linear growth in pass@1 and pass@16 on training data, that means the model improves consistently as RL compute scales. pass@1 means the model gets the answer right on its first try; pass@16 means at least one success across 16 attempts — a measure of reasoning diversity.
Test-Time Reasoning is the third axis. This refers to the compute the model uses at inference time — the period when it’s actually generating an answer for a user. Muse Spark is trained to ‘think’ before it responds, a process Meta’s research team calls test-time reasoning. To deliver the most intelligence per token, RL training maximizes correctness subject to a penalty on thinking time. This produces a phenomenon the research team calls thought compression: after an initial period where the model improves by thinking longer, the length penalty causes thought compression — Muse Spark compresses its reasoning to solve problems using significantly fewer tokens. After compressing, the model then extends its solutions again to achieve stronger performance.
Contemplating Mode: Multi-Agent Orchestration at Inference
Perhaps the most architecturally interesting feature is Contemplating mode. The research team describes it as a novel multi-round test-time scaling scaffold covering solution generation, iterative self-refinement, and aggregation. In plain terms: instead of one model generating one answer, multiple agents run in parallel, each producing solutions that are then refined and aggregated into a final output.
While standard test-time scaling has a single agent think for longer, scaling Muse Spark with multi-agent thinking enables superior performance with comparable latency. This is a key engineering trade-off: latency scales with the depth of a single chain of thought, but parallel agents can add capability without proportionally adding wait time.
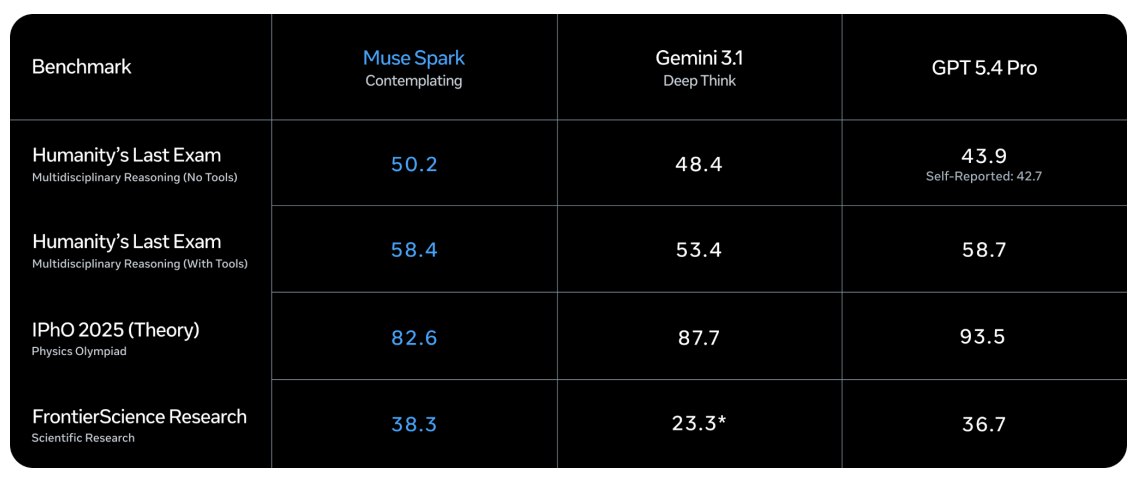
In Contemplating mode, Muse Spark scores 58.4 on Humanity’s Last Exam With Tools — a benchmark designed to test expert-level multidisciplinary knowledge — compared to Gemini 3.1 Deep Think’s 53.4 and GPT-5.4 Pro’s 58.7. On FrontierScience Research, Muse Spark Contemplating reaches 38.3, ahead of GPT-5.4 Pro’s 36.7 and Gemini 3.1 Deep Think’s 23.3.
Where Muse Spark Leads — and Where It Trails
On health benchmarks, Muse Spark posts its most decisive results. On HealthBench Hard — a subset of 1,000 open-ended health queries — Muse Spark scores 42.8, compared to Claude Opus 4.6 Max’s 14.8, Gemini 3.1 Pro High’s 20.6, and GPT-5.4 Xhigh’s 40.1. This is not just luck: to improve Muse Spark’s health reasoning capabilities, Meta’s research team collaborated with over 1,000 physicians to curate training data that enables more factual and comprehensive responses.
On coding benchmarks, the picture is more competitive. On SWE-Bench Verified, where models must resolve real GitHub issues using a bash tool and file operation tool in a single-attempt setup averaged over 15 attempts per problem, Muse Spark scores 77.4 — behind Claude Opus 4.6 Max at 80.8 and Gemini 3.1 Pro High at 80.6. On GPQA Diamond, a PhD-level reasoning benchmark averaged over 4 runs to reduce variance, Muse Spark scores 89.5, behind Claude Opus 4.6 Max’s 92.7 and Gemini 3.1 Pro High’s 94.3.
The sharpest gap appears on ARC AGI 2, the abstract reasoning puzzles benchmark run on a public set of 120 prompts reported at pass@2. Muse Spark scores 42.5 — meaningfully behind Gemini 3.1 Pro High at 76.5 and GPT-5.4 Xhigh at 76.1. This is the clearest current weak spot in Muse Spark’s profile.
Key Takeaways
Meta’s fresh start, not an iteration: Muse Spark is the first model from the newly formed Meta Superintelligence Labs — built on a completely rebuilt pretraining stack that is over 10x more compute-efficient than Llama 4 Maverick, signaling a deliberate ground-up reset of Meta’s AI strategy.
Health is the headline benchmark win: Muse Spark’s most decisive advantage over competitors is in health reasoning — scoring 42.8 on HealthBench Hard versus Claude Opus 4.6 Max’s 14.8 and Gemini 3.1 Pro High’s 20.6, backed by training data curated with over 1,000 physicians.
Contemplating mode trades parallel compute for lower latency: Instead of making a single model think longer — which increases response time — Muse Spark’s Contemplating mode runs multiple agents in parallel that refine and aggregate answers, achieving competitive performance on hard reasoning tasks without proportionally higher latency.
Abstract reasoning is the clearest weak spot. On ARC AGI 2, Muse Spark scores 42.5 against Gemini 3.1 Pro High’s 76.5 and GPT-5.4 Xhigh’s 76.1 — the largest performance gap in the entire benchmark table.
Check out the Technical details and Paper. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us