
OpenAI Just Launched GPT-5.3-Codex: A Faster Agentic Coding Model Unifying Frontier Code Performance And Professional Reasoning Into One System

OpenAI has just introduced GPT-5.3-Codex, a new agentic coding model that extends Codex from writing and reviewing code to handling a broad range of work on a computer. The model combines the frontier coding performance of GPT-5.2-Codex with the reasoning and professional knowledge capabilities of GPT-5.2 into a single system, and it runs 25% faster for Codex users due to infrastructure and inference improvements.
For Devs folks, GPT-5.3-Codex is positioned as a coding agent that can execute long-running tasks that involve research, tool use, and complex execution, while remaining steerable ‘much like a colleague’ during a run.
Frontier agentic capabilities and benchmark results
OpenAI evaluates GPT-5.3-Codex on four key benchmarks that target real-world coding and agentic behavior: SWE-Bench Pro, Terminal-Bench 2.0, OSWorld-Verified, and GDPval.

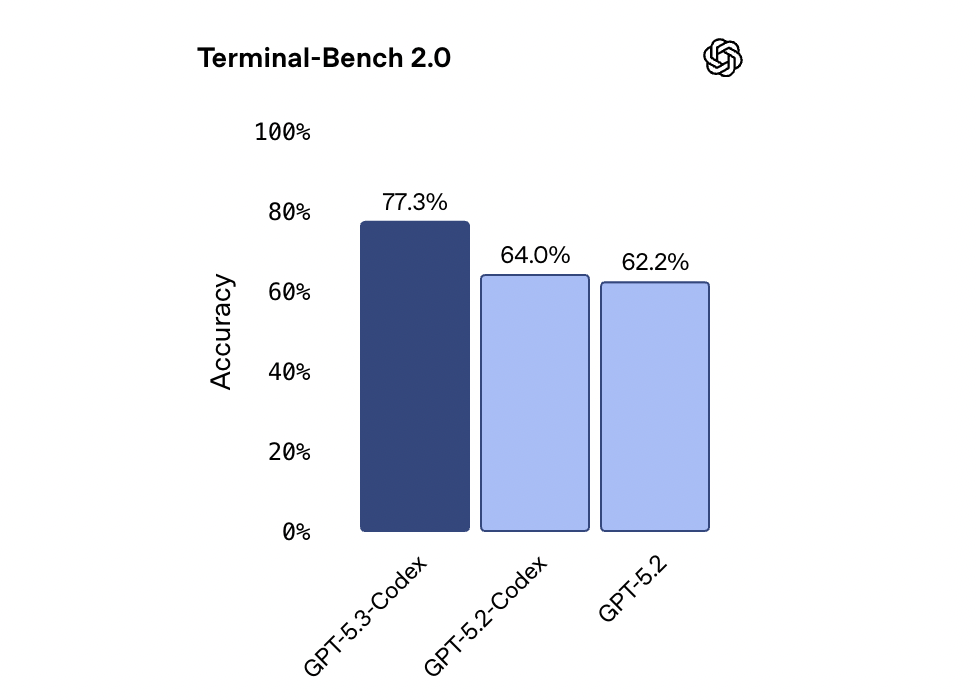
On SWE-Bench Pro, a contamination-resistant benchmark constructed from real GitHub issues and pull requests across 4 languages, GPT-5.3-Codex reaches 56.8% with xhigh reasoning effort. This slightly improves over GPT-5.2-Codex and GPT-5.2 at the same effort level. Terminal-Bench 2.0, which measures terminal skills that coding agents need, shows a larger gap: GPT-5.3-Codex reaches 77.3%, significantly higher than previous models.

On OSWorld-Verified, an agentic computer-use benchmark where agents complete productivity tasks in a visual desktop environment, GPT-5.3-Codex reaches 64.7%. Humans score around 72% on this benchmark, which gives a rough human-level reference point.
For professional knowledge work, GPT-5.3-Codex is evaluated with GDPval, an evaluation introduced in 2025 that measures performance on well-specified tasks across 44 occupations. GPT-5.3-Codex achieves 70.9% wins or ties on GDPval, matching GPT-5.2 at high reasoning effort. These tasks include constructing presentations, spreadsheets, and other work products that align with typical professional workflows.
A notable systems detail is that GPT-5.3-Codex achieves its results with fewer tokens than previous models, allowing users to “build more” within the same context and cost budgets.
Beyond coding: GDPval and OSWorld
OpenAI emphasizes that software devs, designers, product managers, and data scientists perform a wide range of tasks beyond code generation. GPT-5.3-Codex is built to assist across the software lifecycle: debugging, deployment, monitoring, writing PRDs, editing copy, running user research, tests, and metrics.
With custom skills similar to those used in prior GDPval experiments, GPT-5.3-Codex produces full work products. Examples in the OpenAI official blog include financial advice slide decks, a retail training document, an NPV analysis spreadsheet, and a fashion presentation. Each GDPval task is designed by a domain professional and reflects realistic work from that occupation.
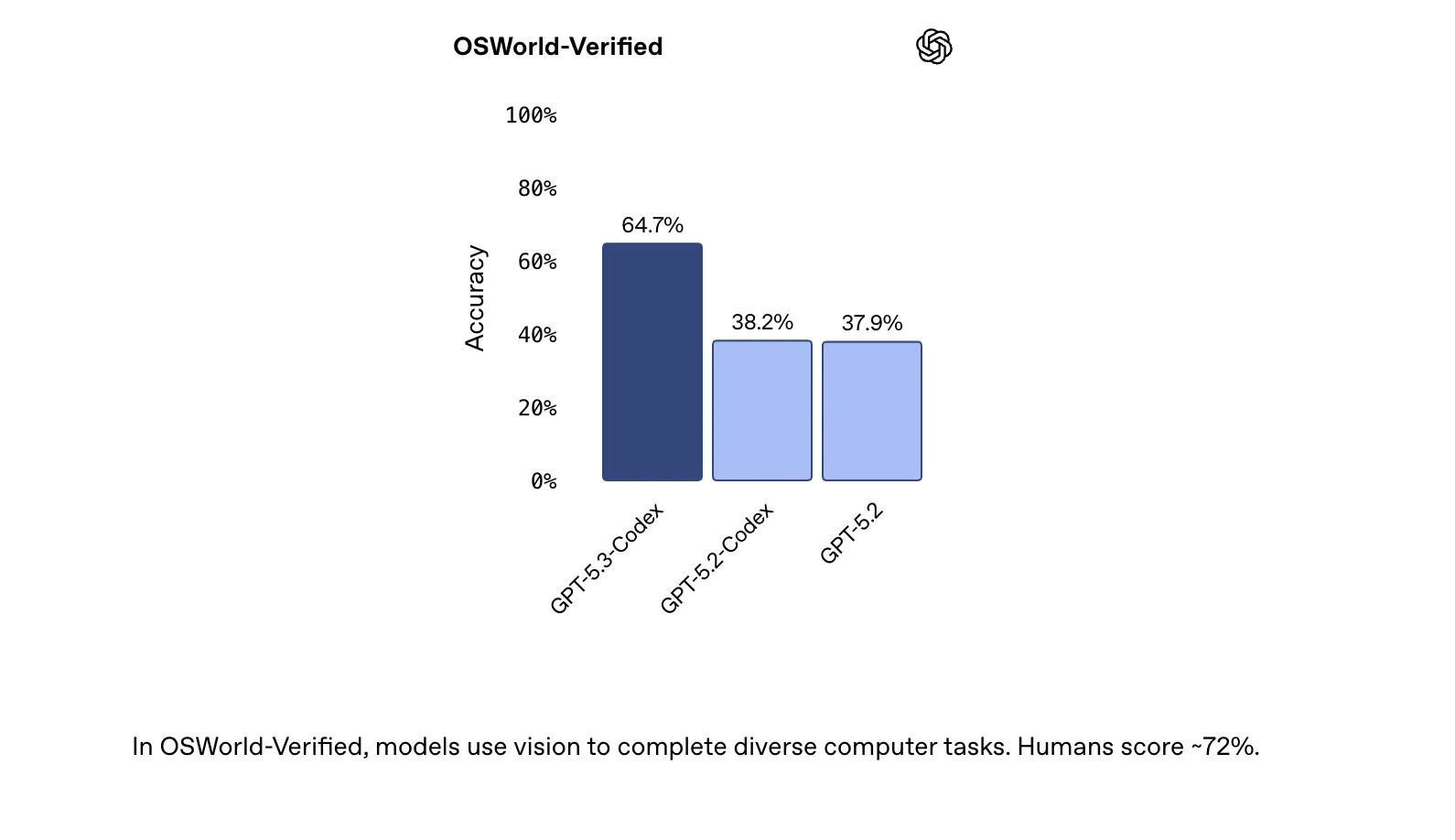
On OSWorld, GPT-5.3-Codex demonstrates stronger computer-use capabilities than earlier GPT models. OSWorld-Verified requires the model to use vision to complete diverse tasks in a desktop environment, aligning closely with how agents operate real applications and tools instead of only producing text.
An interactive collaborator in the Codex app
As models become more capable, OpenAI frames the main challenge as human supervision and control of many agents working in parallel. The Codex app is designed to make managing and directing agents easier, and with GPT-5.3-Codex it gains more interactive behavior.
Codex now provides frequent updates during a run so users can see key decisions and progress. Instead of waiting for a single final output, users can ask questions, discuss approaches, and steer the model in real time. GPT-5.3-Codex explains what it is doing and responds to feedback while keeping context. This ‘follow-up behavior’ can be configured in the Codex app settings.
A model that helped train and deploy itself
GPT-5.3-Codex is the first model in this family that was ‘instrumental in creating itself.’ OpenAI used early versions of GPT-5.3-Codex to debug its own training, manage deployment, and diagnose test results and evaluations.
The OpenAI research team used Codex to monitor and debug the training run, track patterns across the training process, analyze interaction quality, propose fixes, and build applications that visualize behavioral differences relative to prior models. The development team used Codex to optimize and adapt the serving harness, identify context rendering bugs, find the root causes of low cache hit rates, and dynamically scale GPU clusters to maintain stable latency under traffic surges.
During alpha testing, a researcher asked GPT-5.3-Codex to quantify additional work completed per turn and the effect on productivity. The model generated regex-based classifiers to estimate clarification frequency, positive and negative responses, and task progress, then ran these over session logs and produced a report. Codex also helped build new data pipelines and richer visualizations when standard dashboard tools were insufficient and summarized insights from thousands of data points in under 3 minutes
Cybersecurity capabilities and safeguards
GPT-5.3-Codex is the first model OpenAI classifies as ‘High capability’ for cybersecurity-related tasks under its Preparedness Framework and the first model it has trained directly to identify software vulnerabilities. OpenAI states that it has no definitive evidence that the model can automate cyber attacks end-to-end and is taking a precautionary approach with its most comprehensive cybersecurity safety stack to date.
Mitigations include safety training, automated monitoring, trusted access for advanced capabilities, and enforcement pipelines that incorporate threat intelligence. OpenAI is launching a ‘Trusted Access for Cyber’ pilot, expanding the private beta of Aardvark, a security research agent, and providing free codebase scanning for widely used open-source projects such as Next.js, where Codex was recently used to identify disclosed vulnerabilities.
Key Takeaways
Unified frontier model for coding and work: GPT-5.3-Codex combines the coding strength of GPT-5.2-Codex with the reasoning and professional capabilities of GPT-5.2 in a single agentic model, and runs 25% faster in Codex.
State-of-the-art on coding and agent benchmarks: The model sets new highs on SWE-Bench Pro (56.8% at xhigh), Terminal-Bench 2.0 (77.3%), and achieves 64.7% on OSWorld-Verified and 70.9% wins or ties on GDPval, often with fewer tokens than previous models.
Supports long-horizon web and app development: Using skills such as ‘develop web game’ and generic follow-ups like ‘fix the bug’ and ‘improve the game,’ GPT-5.3-Codex autonomously developed complex racing and diving games over millions of tokens, demonstrating sustained multi-step development ability.
Instrumental in its own training and deployment: Early versions of GPT-5.3-Codex were used to debug the training run, analyze behavior, optimize the serving stack, build custom pipelines, and summarize large-scale alpha logs, making it the first Codex model ‘instrumental in creating itself.’
High-capability cyber model with guarded access: GPT-5.3-Codex is the first OpenAI model rated ‘High capability’ for cyber and the first trained directly to identify software vulnerabilities. OpenAI pairs this with Trusted Access for Cyber, expanded Aardvark beta, free codebase scanning for projects such as Next.js.
Check out the Technical details and Try it here. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.










